This section covers all of the information about the data we used for the project as well as the data processing steps and potential sources of data silence. Click the buttons below to view the original dataset as well as the various subsets we created for our analysis.
About the Data
Our original dataset comes from Kaggle, which scraped tweets about ChatGPT during the first month of its launch. It consists of all tweets containing the key word “ChatGPT” between 11/30/2022 and 12/31/2022. The owner of the dataset is Minh Pham, who obtained the data by Twitter API v2 for academic research. The collaborators to this dataset filtered out the raw data with keywords such as ‘chatgpt’ or ‘ChatGPT’ and queried rules such as ‘lang-en’, ‘-is:retweet’, and ‘-is:reply’ so that the dataset contains only English tweets and excludes those that were retweets or replies. The data was already neatly structured and cleaned, without missing values in the columns relevant to our analysis, making it reliable for us to use.
The dataset contains the users’ Tweeter IDs (‘tweet_id’), the time that the tweets were created (‘created_at’), number of likes (‘like_count’), number of quotes (‘quote_count’), number of replies (‘reply_count’), number of retweets (‘retweet_count’), and the tweet’s body content (‘tweet’). The owner’s goal in creating this dataset was to discover people’s perspectives about ChatGPT as well as some questions around this new artificial intelligence technology. Similarly, our team wanted to explore the sentiments around ChatGPT during the initial months of its launch with the aim of exploring whether they are more positive or negative, whether the sentiments differ for different industries, and what benefits and harms such rapid development of artificial intelligence technology may bring to our current society.
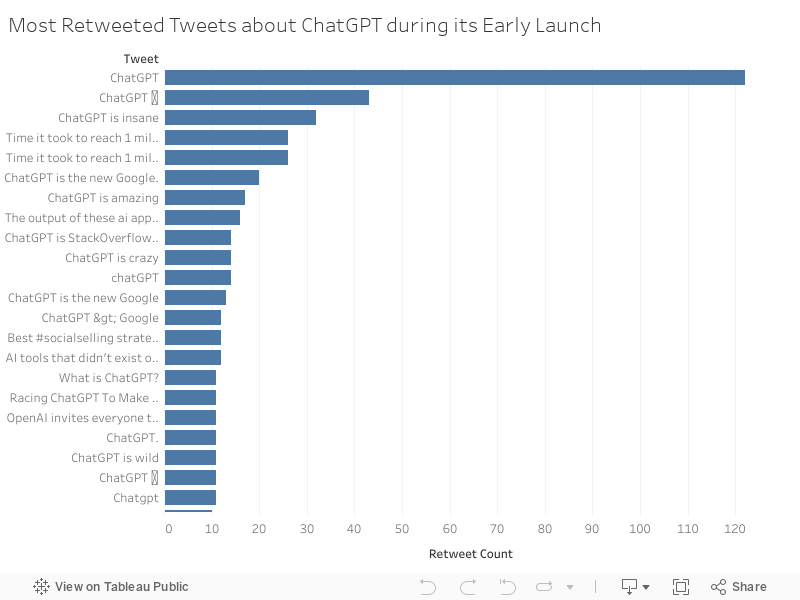
While our dataset only consists of organic tweets, it does include information about the number of retweets and replies for these organic tweets. Upon creating visualizations to explore the most retweeted and liked tweets, we noticed that there is a substantial amount of overlapping tweets between the two; mostly the same tweets had the most likes and retweets. This sheds light on the dominant outlook towards ChatGPT overall, since the tweets that seemed to be getting the most traction were those that people liked, expressing excitement and marvel at the new product. This is expected, as our dataset is taken from the time around ChatGPT’s initial release before any major concerns could have the chance to surface. Most of the top tweets expressed responses like “ChatGPT is amazing” or “ChatGPT is insane”.
Data Processing
Technical Specifications
We first used Voyant Tools to conduct some exploratory research on our dataset as a whole as well as within specific industries from the data subsets we created using Google Sheets. Google Sheets allowed us to easily filter our relevant tweets for each subset by using the same formula but just different keywords relevant to each industry. We chose Voyant Tools for initial visualizations because it’s easy to use and helpful for beginners doing early-stage research, as we can get a general sense of patterns in the data through frequency charts, word clouds, and collocate graphs. Since our research heavily depends on sentiment analysis, we then used R – specifically, the Vader package to get sentiment scores of our whole dataset and subsets, so that we could then compare the sentiment between different industries and see if there are any striking differences, and the Syuzhet package to create a sentiment bar graph to identify the most dominant attitudes in our data. We then utilized the dplyr and ggplot2 libraries in R to take the compound scores we obtained from Vader to create donut charts visualizing the sentiment score breakdown for each industry. We also used Excel to make one of the donut charts, as this chart was more aesthetically pleasing. These donut charts made it easier for us to visually analyze differences and similarities in sentiment across industries. We also used Tableau for visualizing sentiment compound scores in different ways such as creating a bar chart of tweets’ compound scores, which allowed us to get a detailed view of how every individual tweet was being scored in order to determine accuracy of our results. Tableau was useful to create various different charts comparing two variables together, such as time and tweet count or time and compound score.
Description of Work Plan
We started off by creating our data subsets in Google Sheets by filtering tweets from the original dataset that contained keywords pertaining to the industry sectors we are interested in, such as technology, education, and marketing. This gave us individual subsets we could use to separately analyze ChatGPT in the technology sector, marketing sector, education sector, and employment. This was an important step for us to be able to answer our research questions that explore overall public sentiment towards the tool and how different industries are responding to the rise of ChatGPT, as well as get a sense of how it is further impacting employment.
We noticed that the primary participants in the Twitter conversation of ChatGPT were professionals or the vocal ones in different industries. Ultimately, they are the ones who make sentimental statements about ChatGPT regarding their respective industries. These participants are from the marketing, education, employment, and tech industries, which are the most relevant to our research compared to other industries as they are concerned with the utilization and development of chatbots. It was interesting to note that from our dataset, the most vocal industry in the Twitter conversation was the technology industry, which had the most tweets about ChatGPT among all industries, summing up to 12,894 tweets. This highlights that the general sentiment in our dataset will be leaning toward the technology industry, prompting us to analyze them to a greater degree and derive more meaningful insights.
In our project, we performed quantitative and sentiment analysis to analyze our data. Using Tableau and R, we created data visualizations to portray our sentiment analysis on tweets surrounding the topic of ChatGPT, some examples including sentiment scores graphs, sentiment word frequency graph, compound scores, and more. To analyze specific positive, negative, and neutral sentiments, we also made use of word maps generated from Voyant Tools, which helped us analyze stronger, specific sentiments and get a general overview of different views regarding the AI technology. Such uses of different visualizations and tools pertain to our broader analytical approach to our project.
Delving deeper into the technical specifics, we centralized our analyses on sentiment compound scores as well as word frequencies within text analysis. For instance, in the “Sentiments towards ChatGPT in Tech industry from 11/30/22 to 12/31/22” graph, we observe the frequencies of words in tweets that pertain to each of the particular sentiment words such as “joy” and “anger”. Moreover, in analyzing the general sentiments around ChatGPT, we analyze the top positive as well as the top negative tweets to demonstrate examples of tweets that are classified as positive and negative, directly looking at what people are conversing about the novel technology. In doing so, we ran Vader Scripts on each of our subsets to obtain different sentiment scores, and moved them to Tableau to visualize the numbers. We chose to mainly use the R software and Tableau because they both make working with numerous rows of data very feasible and are beginner-friendly, but also widely used by many users as reliable data analysis and visualization tools.
Data Silence
Though our dataset seems to provide numerous rows of tweets, there are some instances of data silence that make our analysis not completely perfect. First, because the dataset was filtered out to include only English tweets, we are limited in terms of the inability to analyze the global sentiments around ChatGPT. This could pose a challenge since ChatGPT is not only affecting the United States, but also other countries as the technology continues to advance in most regions. Moreover, our dataset does not contain any location data, which makes it hard for us to understand the full context of the individual tweets. Furthermore, our dataset only contains organic tweets as the dataset pre-excluded all retweets and replies. Such instances of data silence make it hard for us to conduct a perfect analysis, but with the given dataset and the subsets that we created in the processing stage, we aim to thoroughly answer our research questions and provide insightful findings.